Table of content
1. DynamoDB Partitioning 원리
- DynamoDB는 자체 내부 Hash Function이 있다.
- Partition Key값을 파라미터로 계산된 Hash Value를 기준으로 DynamoDB Table 내부의 파티션이 결정되어 데이터는 적재된다.
- Primary Key가 복합키인 경우에도 단일 Partition Key로 이루어진 경우와 같은 방식으로 partition key hash값을 계산하여 partition에 적재한다.
- 그러나 같은 partition key를 가진 데이터들은 물리적으로 가깝게 설계되며, Sort Key 값으로 정렬된다.

2. Partition Key 설계시 고려사항
2-1. 분산된 워크로드
- Partition Key는 테이블에서 데이터가 저장되는 논리적 및 물리적 파티션을 결정하는 요소이다.
- DynamoDB는 결정된 파티션들에게 프로비저닝된 Capacity Unit을 균일하게 분배한다.
- 즉, Partition Key의 분산도를 고려하지 않고 설계시, 요청에 대해 효율적인 Capacity Unit을 사용할 수 없게 된다.
- 물론 DynamoDB는 관리형 서비스이기 때문에 어느정도 조절은 해 주지만, 최적화를 위해서는 위 관리형 서비스에 의존하지 않고, 직접 튜닝하는 것이 적절하다.
다음 데이터는 실제로 필자가 DynamoDB를 학습하며 설계하였던 테이블이다. (나중에 이 테이블을 보니 최악이었다 :( )

위 테이블의 경우, 사내 회의실 예약 시스템에 대한 정보를 구현하기 위해 설계한 내역이며, partition key가 INFO_TYPE이며, sort key가 HASH_VALUE로 설계되었다.
현재 위 테이블의 Partition Key의 값은 단 2개로 나뉘어져 있다. 위 DynamoDB Partition 아키텍처는 다음과 같이 그림으로 나타낼 수 있다.

위 아키텍처를 염두에 두고 생각해보자. 회의실의 개수는 건물에 한정적이고, 이 한정적인 회의실에서는 수많은 직원들이 회의실을 사용한다.
그러므로 상대적으로 회의실 정보보다 예약 정보가 훨씬 많을 것이고, 데이터에 대한 접근도 예약정보가 훨씬 많을 것이다.
그 결과, 같은 Capacity Unit을 제공받은 partition이지만, I/O요청이 압도적으로 많은 "res" partition key를 가진 파티션은 그만큼 비효율적인 요청처리를 하게 된다.
다음 아키텍처는 위 아키텍처를 조금이나마 개선한 아키텍처이다. (극단적인 예시이므로 참고만 해주길 바란다.)

위같이 설계를 바꾼 이유는 다음과 같다.
- 회의실에 대한 예약은 현재 HASH_VALUE값 자체를 이용하며, [회의날짜]#[회의실]#[회의시작시간]#[회의종료시간] 의 format을 가진다.
- 시간의 흐름 중에서 뽑은 하나의 시간 표본은 유일하다.
- HASH_VALUE도 시간 값 이므로, 유일한 값이다.
- 위 HASH_VALUE를 Partition Key로 설계하면 Partition의 분포도가 좋아진다.
- 그러므로 한 파티션에 대한 I/O 병목현상이 개선될 수 있다.
2-2. Partition Key에 난수 추가 (Sharding)
-
Sharding은 Partitioning의 한 부분이며, "Horizontal Partitioning"과 같은 의미이다.
- 기존 설계한 Partition Key에 난수를 추가하게 되면, Hash Function에 의해 결과값이 다양해진다.
- 그 결과로 DynamoDB 내부의 논리적 및 물리적 파티션의 분포는 분산된다.
- 파티션이 분산됨에 따라 병렬처리를 개선할 수 있다.
2-3. Partition Key를 이용한 효율적인 쓰기 작업 분산
- DynamoDB는 기본적으로 파티션의 크기와는 상관 없이 균일한 Capacity Unit을 할당받는다.
- DynamoDB는 관리형 서비스이기 때문에 어느정도 파티션간 Capacity Unit을 프로비저닝 해주지만, 이에 의존한 key설계는 올바르지 못하다.
- 그러므로, 쓰기 작업에 대해서도 타겟 파티션을 분산시켜 정의할 필요가 있다.
case1. partition key의 정렬 순서대로 데이터를 쓰는 경우
- 위와 같이 쓰기작업을 정의할 시, 한 파티션의 Capacity Unit을 집중적으로 쓰기 때문에 병목현상이 발생 할 수 있다.

case2. partition key의 순서와 무관하게 분산시켜 데이터를 쓰는 경우
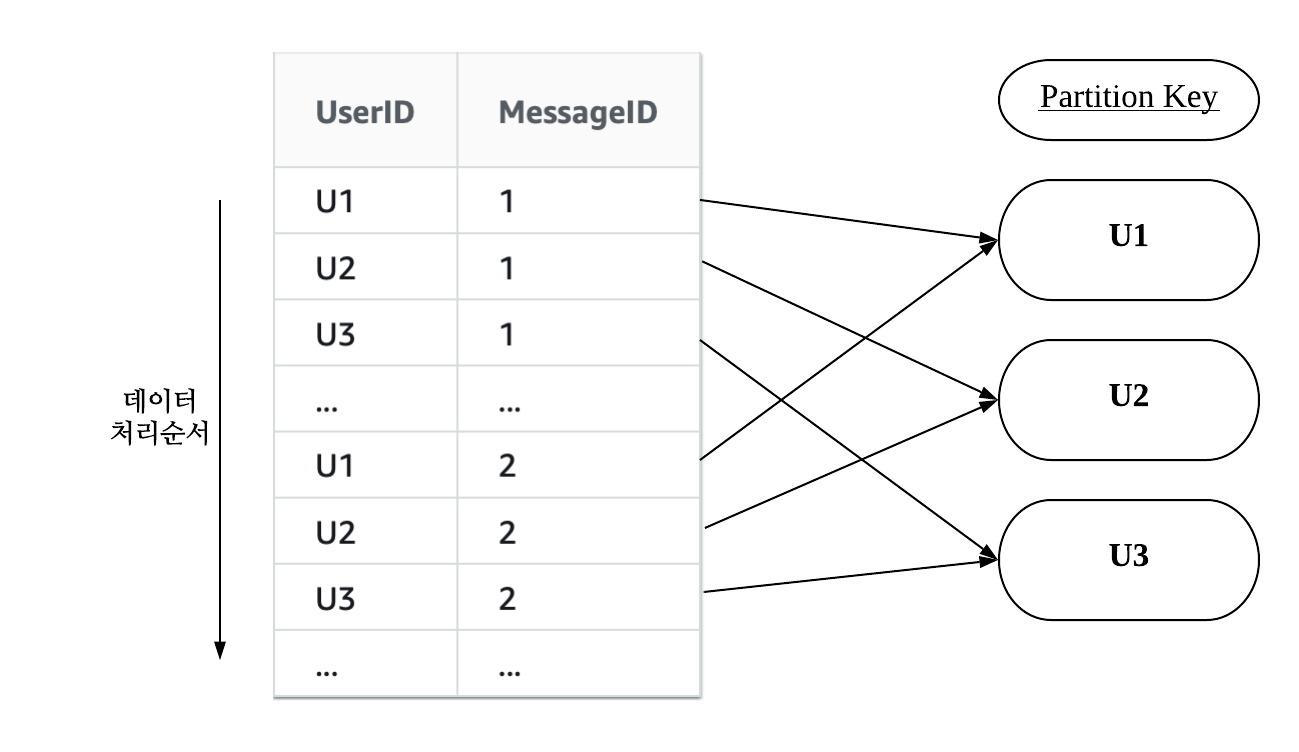
- 위와 같이 쓰기 작업을 개선할 시, 매 작업마다 다른 파티션의 Capacity Unit을 사용하기 때문에 case1 보다 Capacity Unit의 사용률에 대해 보다 유연하게 대처 가능하다.
3. 참고문헌
'IT > NOSQL' 카테고리의 다른 글
| [MongoDB] Timeseries Collection에 대한 연구 (1) | 2022.03.17 |
|---|---|
| [MongoDB] MongoDB Performance를 향상시키는 전략 (0) | 2021.09.22 |
| [DynamoDB] Secondary Index 설계원칙 및 고려사항 (0) | 2020.02.18 |
| NoSQL vs RDS (0) | 2019.11.19 |
| [DynamoDB] Amazon DynamoDB 구성 요소 (0) | 2019.11.19 |