0. Table Of Contents
1. 설계 배경
개인 프로젝트를 진행하던 도중 업로드한 개인 프로필 사진을 저장해야하는 기능을 개발하게 되었다. 프로필 사진을 저장하고 불러오는 단계에서 최대한의 성능을 내게 하고자 고민하게 되었다.
2. 고려해야할 항목
- 사진파일이 올라갈 때 너무 큰 크기의 사진이 올라가게 되면 돈을 많이 내게 된다.
- 사진 파일이 올라간 aws s3경로를 보고 이 사진이 어떤 사진인지 확실하게 알면 좋다.
- AWS S3도 내부적으로 파일을 찾을 때 성능적인 문제가 생긴다고 하던데, 이를 고려한 설계가 들어가면 좋다.
3. AWS S3 Reference 분석
AWS 내부적으로 S3 Bucket에서 파일을 어떻게 분포시키느냐에 따라 search 성능이 떨어질 수 있다고 들은게 있기 때문에 이에 대해서 성능적인 이슈를 하나씩 찾아본 결과, aws official blog를 찾을 수 있었고, 이를 아래에 요약을 해보았다.
S3에는 splitting이 필요한 keyspace를 지속적으로 모니터링하는 자동화기능이 있습니다. 내부적으로 high rate request, 너무 많은 key(aws s3 object) 등의 요소에 따라 파티션을 새로 생성하여 key를 이동시킵니다. 이러한 작업이 성능적으로 큰 영향을 미치진 않지만, 단일 파티션에 많은 key에 대해 request rate가 증가하면 이러한 작업이 많이 발생하기 때문에 사전에 내부적으로 파티셔닝이 많이 일어나지 않는 key path 설계를 하는 것이 중요합니다.
3.1. 문제상황 예시
위 요약 내용을 설명하기 위해 아래에 예시를 통해 알아보도록 하자.
당신이 쓰기 및 읽기가 많이 이루어지는 파일들을 다음과 같은 형식으로 Service라는 bucket안에 s3 key로 만들었다고 가정하자.
bucket/user/schedule/<userId>
bucket/user/info/<userId>
bucket/user/secret/<userId>
bucket/user/company/<userId>
bucket/user/log/<userId>
위 같은 경우처럼 설계되었을 시, 유저가 요청하면 aws는 아래 그림과 같이 aws key를 탐색한다.
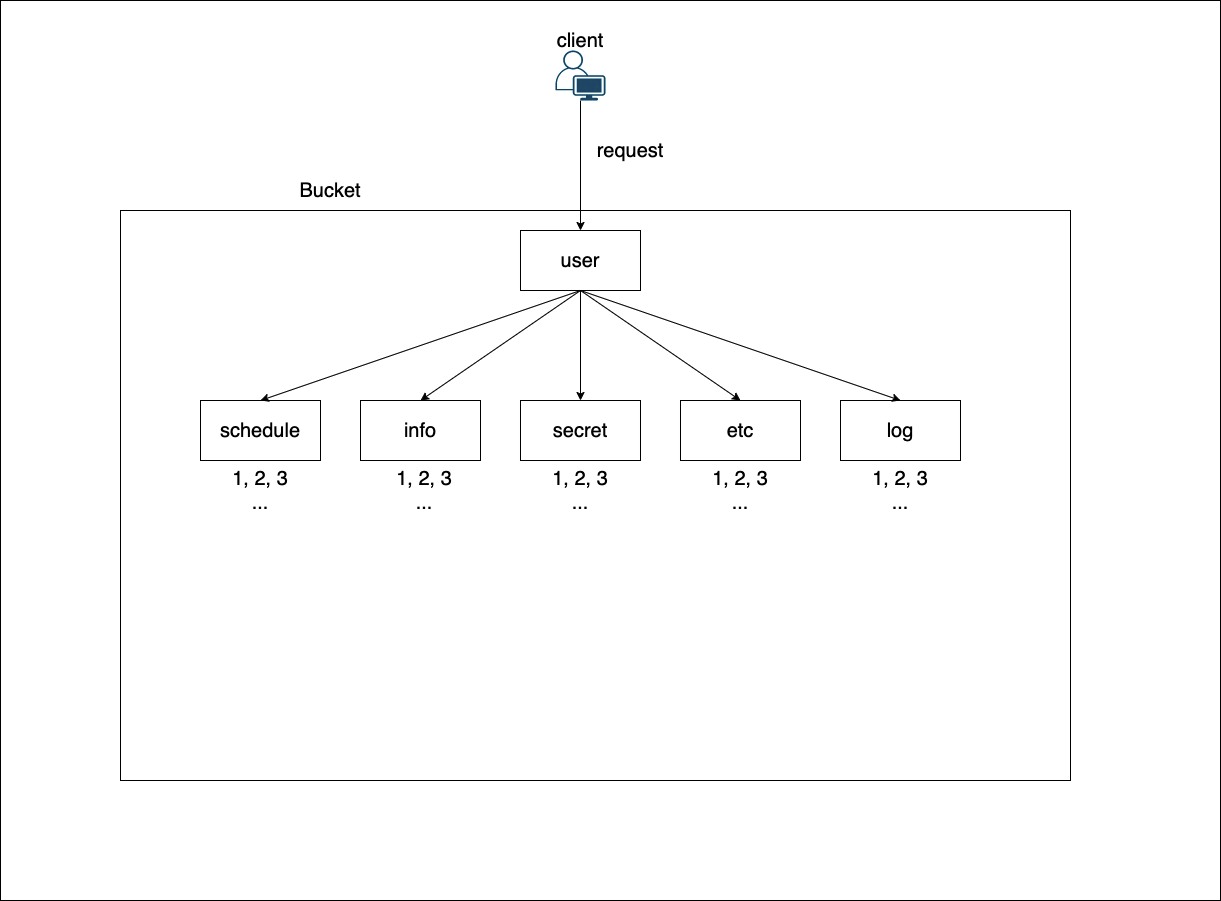
위 그림과 같은 아키텍처에서 엄청나게 많은 요청이 들어왔을 때, user 디렉토리에 부하가 많이 걸릴 것이다. 이 결과로 aws s3 내부적으로는 부하를 해결하기 위해 파티셔닝이 일어날 것이다.
3.2. 문제상황 해결
위 3.1 그림에서 한 디렉토리로 request가 몰리지 않도록해보자. 가장 분포가 넓은 것을 위주로 key path를 설계를 한다면 기존 user라는 디렉토리로 과부하가 read/write 요청이 몰리지 않을 것이다.
위 사진에서 가장 분포가 넓고 공통점을 많이 가진 key path를 재설계해보았을 때 아래와 같은 구조를 생각해볼 수 있다.
bucket/<userId>/schedule
bucket/<userId>/info
bucket/<userId>/secret
bucket/<userId>/etc
bucket/<userId>/log
.
.
.
위 구조를 모식화 하면 아래 사진과 같다.
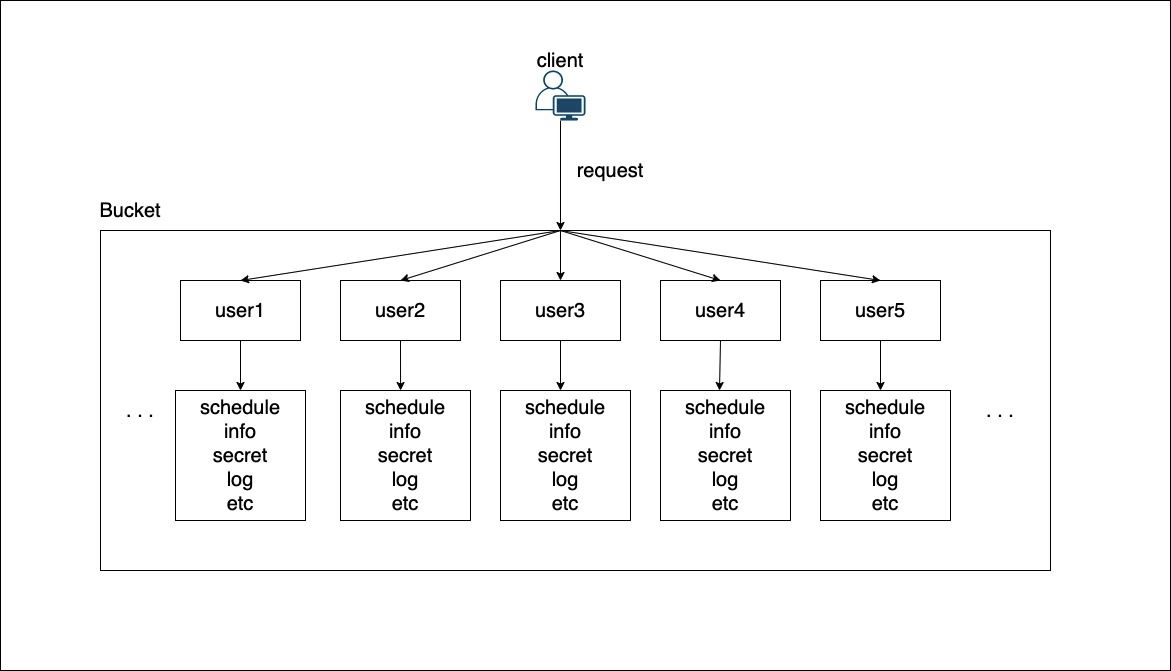
초안보다 개선된 점은 다음과 같다.
1. 기존 user 디렉토리를 여러명의 유저 개개인 관점으로 쪼개어 하나의 디렉토리로 몰리지 않게 함.
2. 유저의 속성으로 쪼갤 수 있었으나, 유저의 속성(schedule, info, secret…)보다는 userId 값이 분포가 훨씬 넓기 때문에 userId로 쪼갠 것이 부하분산에 유리하다.
4. 실전 적용
표현해야하는 정보 및 고려사항은 다음과 같다.
- 유저 프로필 사진을 업로드하고, 경로를 보고 이 사진이 어떤 사진인지 알 수 있어야 한다.
- S3 key 이름에 특정인이 암시되지 않아야 한다.
- key를 가지고 버전관리가 되어야하며, 지난 사진은 삭제시켜야한다.
- 프로필 사진의 크기가 여러개 존재할 수 있다.
이 사항들과 위 내용을 고려한 결과, 다음과 같은 s3 key path를 설계할 수 있었다.
bucket/<USER_ID>/profile/<IMG_SIZE>/<TIMESTAMP>
- <USER_ID> : 유저의 고유 id
- profile : 유저의 프로필 사진이라는 뜻의 path, 유저의 다른 부분들이 저장될 수 있기 때문에 이 부분을 유저의 어떤 자원인지 명시해주기로 함.
- <IMG_SIZE> : 200x200, 400x400같이 해당 사진의 크기가 몇인지 표시해주는 path
- <TIMESTAMP> : 원본 사진 파일 이름을 알 필요가 없으며, 주기적으로 aws lambda를 이용해 timestamp가 오래된것들은 삭제시킬 수 있다.
5. 결론 및 느낀점
- Cloud 자원 역시 근본은 데이터센터 자원을 사용하는 것이기 때문에, 최대한의 효율을 낼 수 있는 방법을 충분히 리서치를 하여 적용시키는 방법이 더 바람직하다.
- 위 aws s3 key설계가 현재 학습 중인 mongoDB의 get 부하분산이랑 되게 비슷하다는 느낌을 받았다.
6. Reference
'IT > Cloud' 카테고리의 다른 글
| [FaaS Service] FaaS Service를 사용시 주의해야할 점 (0) | 2021.07.16 |
|---|---|
| [Docker-Compose]Docker-Compose env parsing error로 인한 삽질기록 (0) | 2021.06.24 |
| [AWS] Site to Site VPN with OpwnSwan구성하기 (64) | 2020.05.09 |
| [Amazon SES] Simple Email Service Sample (31) | 2020.04.08 |
| [AWS-CLI] aws: command not found 해결법 (0) | 2019.11.14 |