0. Table Of Contents
1. 개요
여러 서비스로 쪼개져 있는 환경에서는 각 마이크로서비스가 필요한 인덱스를 build 할 수 있다. 그러나, 인덱스를 개발자 간 상호 협의 없이 각자 필요한 인덱스를 수시로 빌드하여 사용하다보니 불필요한 인덱스가 생기면서 비용적인 낭비가 발생하게 되었다.
따라서 이에 mongodb 튜닝을 진행하여 최적화 시키는 작업을 진행하고자 한다.
2. 배경 지식
2.1. 인덱스
데이터가 저장된 위치를 key-value 형태로 표현하며 검색속도를 향상시키기 위해 존재하는 데이터이다. 인덱스는 새로운 데이터가 기록될 때 마다 새로운 순서로 계속 정렬을 하기 때문에 쓰기가 느리지만, 이미 정렬되어있기 때문에, 특정 데이터를 찾아오는 작업에 대해서는 매우 빠른 속도를 보장한다.
그러나 인덱스가 DB의 성능을 무조건 향상시키는 것은 아니다. 인덱스는 위에서 언급한 것 처럼 새로운 순서로 지속적으로 계속 정렬을 하기 때문에 쓰기가 많이 일어나는 환경에서 불필요한 인덱스를 생성하나 복잡한 인덱스가 존재하면 오히려 DB의 성능을 떨어뜨릴 수 있다.
2.2. B-Tree
기존 이진트리는 노드 하나에 하나의 데이터밖에 저장할 수 없지만, 이를 개선하여 노드 하나에 여러개의 데이터를 저장할 수 있도록 개선한 자료구조이다. 노드에 자료가 몇개 있으냐에 따라 n차 B-Tree라고 부른다.

출처 : By CyHawk - Own work based on [1]., CC BY-SA 3.0 (https://commons.wikimedia.org/w/index.php?curid=11701365)
2.3. B-Tree에 최적화된 mongodb index 설계
MongoDB 공식 document에 따르면, index는 ESR Rule를 따르는 것이 가장 좋다고 설명되어있다.
2.3.1. ESR Rule
ESR은 각각 Equality, Sort, Range를 의미하며, 아래의 rule을 따라야 한다.
- Query에서 Equality에 대한 부분을 먼저 배치한다.
- 그 다음 query의 order를 반영하는 필드가 반영이 되어야 하며,
- 마지막에 range를 고려한다.
2.3.2. 왜 ESR Rule을 따라야 하는가?
위 B-Tree 데이터를 보면서 생각을 해보자. 우리는 단순 사람이름과 시험 점수에 대한 데이터를 저장하고 있는 exam collection에 대해 compound index를 만들어야 하는 상황이다. 그러면 당신은 어떻게 index를 설계할 것인가
2.3.2.1. E와 R의 관계
단순 find를 할 시, 우리는 아래와 같은 케이스를 생각 할 수 있을 것이다.
exam.find({"score":{$gte:60}}, studentName:"dummy")
exam.find({studentName:"B", "score":{$gt:80}})
첫번째 케이스에 대해 탐색하는 것을 모식도로 그려보면 다음과 같다.

위 find query를 따라가면, 먼저 60점 이상의 점수를 찾아야 하므로 4개의 노드를 참조 할 것이다. 그다음 B라는 value를 가진 studentName을 찾아야 하기 때문에, 또 4개의 key를 더 탐색해야하므로 총 8개의 key를 탐색 할 것이다.
두번째 케이스에 대해 탐색하는 것을 모식도로 그려보면 다음과 같다.

두번째 케이스 query를 분석하게 되면 A,B,C 중 해당 되는 노드만 참조하면 되기 때문에 위 케이스와 비교하였을 때 훨씬 참조하는 노드가 적어진다. 따라서 참조하는 노드가 적어지는 만큼 search 시간도 빨라진다.
3. 개선 전 DB 문제점 분석
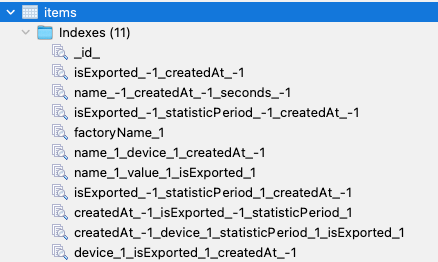
서로가 필요한 인덱스를 협의없이 생성을 하다보니 비슷한 형태의 인덱스도 많고 쓰지 않는데 선언이 되어있다보니 프로젝트가 실행될때마다 불필요한 인덱스를 만드는 비효율적인 루틴을 지속해서 실행하고 있었다. 인덱스가 선언된 부분과 기타 외적인 부분을 분석한 결과 아래와 같은 문제점을 도출해 낼 수 있었다.
- index prefix를 사용하지 않아 불필요한 인덱스가 있음.
- 비슷한 유형의 인덱스는 협의하에 통일 할 수 있었으나 그러지 못한 인덱스가 존재
- 특정 인덱스의 경우 카디널리티가 작은 key에 대해서도 인덱스가 생성이 되어있어 비효율적인 부분이 발생할 수 있음
- ESR rule에 맞지 않는 인덱스가 존재하였다
위 문제점들이 맞는지에 대한 검증과 추가적인 문제점이 있는지 분석을 해보기로 하였다.
3.1. 불필요한 인덱스
아래 query결과는 현재 aggregation 대상이 된 collection의 index가 얼마나 참조되고 있는지에 대한 현황을 나타낸다.
아래 결과에서 access부분을 유심히 관찰해보자.
db.items.aggregate([{$indexStats:{}},{$project:{name:1, accesses:1}}])
/* 1 */
{
"name" : "device_-1_name_-1_statisticPeriod_-1_createdAt_-1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 2 */
{
"name" : "device_1_isExported_1_createdAt_-1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 3 */
{
"name" : "device_-1_name_-1_statisticPeriod_-1",
"accesses" : {
"ops" : NumberLong(604388),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 4 */
{
"name" : "isExported_1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 5 */
{
"name" : "_id_",
"accesses" : {
"ops" : NumberLong(604039),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 6 */
{
"name" : "createdAt_-1_isExported_-1_statisticPeriod_1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 7 */
{
"name" : "isExported_-1_statisticPeriod_-1_createdAt_-1",
"accesses" : {
"ops" : NumberLong(604388),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 8 */
{
"name" : "isExported_-1_createdAt_-1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 9 */
{
"name" : "createdAt_1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 10 */
{
"name" : "device_-1_name_-1_createdAt_-1",
"accesses" : {
"ops" : NumberLong(3444352),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 11 */
{
"name" : "name_1_value_1_isExported_1",
"accesses" : {
"ops" : NumberLong(604388),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 12 */
{
"name" : "factoryName_1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
accesses.ops가 0인 부분들이 많이 보인다. 즉, 한번도 사용 안되는 인덱스들이 존재하며, insert 될 때마다 이 인덱스들이 정렬되고 있다는 증거이다.
/* 1 */
{
"name" : "device_-1_name_-1_createdAt_-1",
"key" : {
"device" : -1,
"name" : -1,
"createdAt" : -1
},
"host" : "DESKTOP-TN7G775:27017",
"accesses" : {
"ops" : NumberLong(3456588),
"since" : ISODate("2022-07-05T10:52:12.533Z")
},
"spec" : {
"v" : 2,
"key" : {
"device" : -1,
"name" : -1,
"createdAt" : -1
},
"name" : "device_-1_name_-1_createdAt_-1",
"background" : true
}
}
/* 2 */
{
"name" : "device_-1_name_-1_statisticPeriod_-1",
"key" : {
"device" : -1,
"name" : -1,
"statisticPeriod" : -1
},
"host" : "DESKTOP-TN7G775:27017",
"accesses" : {
"ops" : NumberLong(606924),
"since" : ISODate("2022-07-05T10:52:12.533Z")
},
"spec" : {
"v" : 2,
"key" : {
"device" : -1,
"name" : -1,
"statisticPeriod" : -1
},
"name" : "device_-1_name_-1_statisticPeriod_-1",
"background" : true
}
}
/* 3 */
{
"name" : "name_1_value_1_isExported_1",
"key" : {
"name" : 1,
"value" : 1,
"isExported" : 1
},
"host" : "DESKTOP-TN7G775:27017",
"accesses" : {
"ops" : NumberLong(606925),
"since" : ISODate("2022-07-05T10:52:12.533Z")
},
"spec" : {
"v" : 2,
"key" : {
"name" : 1,
"value" : 1,
"isExported" : 1
},
"name" : "name_1_value_1_isExported_1",
"background" : true
}
}
/* 4 */
{
"name" : "_id_",
"key" : {
"_id" : 1
},
"host" : "DESKTOP-TN7G775:27017",
"accesses" : {
"ops" : NumberLong(606575),
"since" : ISODate("2022-07-05T10:52:12.533Z")
},
"spec" : {
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
}
}
/* 5 */
{
"name" : "isExported_-1_statisticPeriod_-1_createdAt_-1",
"key" : {
"isExported" : -1,
"statisticPeriod" : -1,
"createdAt" : -1
},
"host" : "DESKTOP-TN7G775:27017",
"accesses" : {
"ops" : NumberLong(606924),
"since" : ISODate("2022-07-05T10:52:12.533Z")
},
"spec" : {
"v" : 2,
"key" : {
"isExported" : -1,
"statisticPeriod" : -1,
"createdAt" : -1
},
"name" : "isExported_-1_statisticPeriod_-1_createdAt_-1",
"background" : true
}
}
그러나 이제 눈에 보이는 것은 MongoDB의 ESR Rule에 따르지 않은 것들이 눈에 보인다. 이를 개선하기 위해 몇개의 쿼리를 더 실행하여보자.
3.2. 인덱스 카디널리티 분석
카디널리티란, 간단히 말하여 데이터의 중복도를 의미한다. 즉, distinct를 하였을 때 더 많은 컨텐츠가 나오면 카디널리티가 높다고 말할 수 있다.

카디널리티가 낮은 키들을 추린 결과 아래와 같다.
- isExported : true or false
- factoryName : 해당 사이트이름
- seconds : 1~60 고정
- statisticPeriod : 10
이 키들을 대상으로 인덱스를 만들게되면 애초에 카디널리티가 매우 낮기 때문에, B-Tree 구조를 가진 인덱스를 만들더라도 효과가 거의 없는 수준이다. 따라서 이 인덱스를 정말로 필요하지 않는 한 제거하기로 결정을 하였다.
3.3. ESR Rule 분석
Equality-Sort-Range의 기준으로 인덱스가 작성이 되어야 가장 효율적인 인덱스를 빌드 할 수 있다. 그러나 위 명시된 key 순서에서 해당 조건을 만족시키지 못하는 인덱스 들이 많이 보인다. 대표적으로 createdAt 키가 가장 앞에 오는 인덱스이다. 일반적으로 sort나 range 검색에 자주 쓰이는 key지만 맨 앞에 위치하고 있기 때문에, B-Tree 구조를 가진 인덱스 동작을 생각해보면 불필요한 노드가 여러개 생길 수 있으므로 기존보다 용량을 더욱 많이 차지할 것으로 예상된다.
ESR Rule에 어긋나는 인덱스를 추려보면 아래와 같다.
- {name:-1, createdAt:-1, seconds:-1}
- {name:-1, device-1, createdAt:-1}
먼저 첫번째 인덱스를 살펴보면
name의 경우에는 equality 속성을, createdAt은 range + sort 속성, second는 backend service에서 $in operator 를 사용하고 있었기 때문에 equality속성을 지니고 있다. ESR rule에 따르면 equality가 먼저 취급되어야 하지만, 이 인덱스는 그러하지 못하였다. 또한, second 의 경우 카티널리티가 낮은 인덱스이기도 하기 때문에 인덱스 효과를 보기 미미하다고 판단하였다.
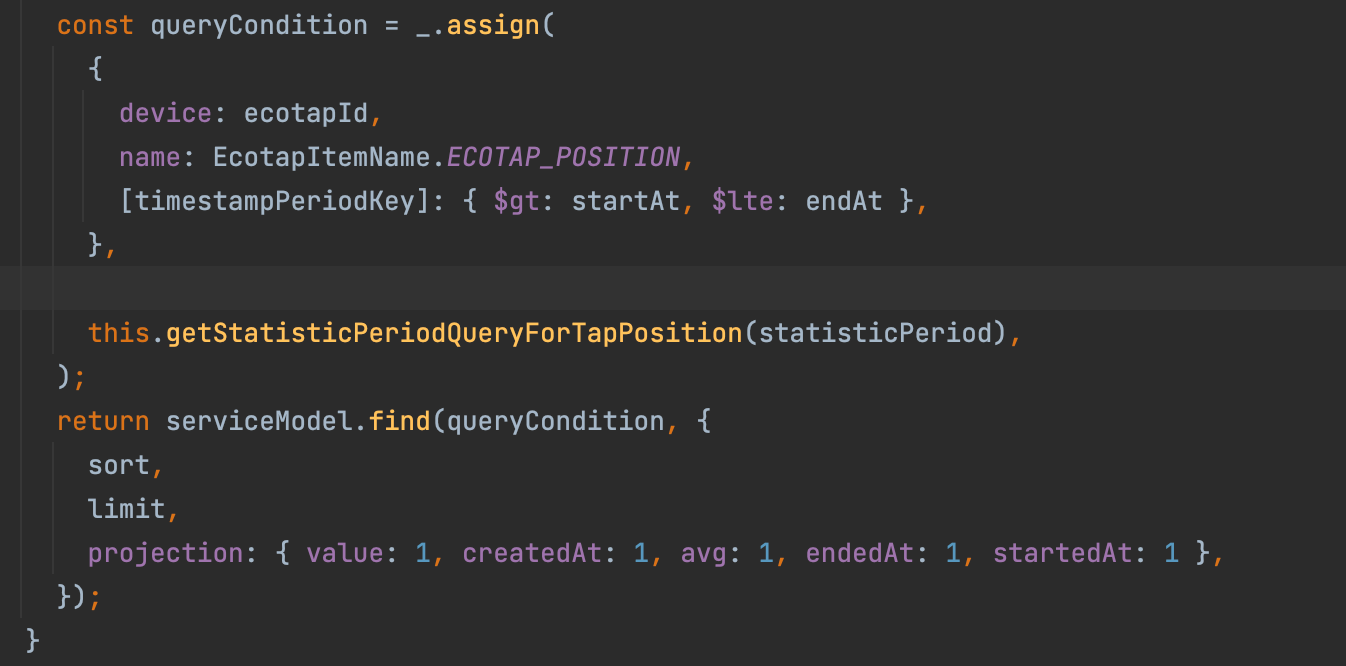
실제로 위와 같은 mongodb find query가 사용되고 있었으며, 위 쿼리가 의도하지 않은 인덱스인 {name:-1, createdAt:-1, seconds:-1}를 타고 있었기 때문에 이를 개편하기로 결정하였다.
쿼리에서 사용한 key는 아래와 같다.
- device : 데이터를 받는 장비의 objectId
- name : 데이터의 이름
- createdAt : 데이터가 만들어진 시점 (실시간성이 있기 때문에 쿼리시, 가장 최근 기준으로 데이터를 많이 불러옴.)
위 key 중 createdAt는 sort 및 range에 해당하는 key이기 때문에 맨 뒤로 인덱스 우선순위를 미뤘으며, 현재는 비슷한 카디널리티의 분포이지만 향후 수집하는 기기의 수가 더 많아지면 device key가 name보다 더 카디널리티가 높게 나타날 것이다. 높은 카디널리티 key를 인덱스에 우선 배치를 하게 되면 그만큼 사전에 filter 되는 데이터의 수가 더 많아지게 되기 때문에 index scan을 줄이는 효과를 얻을 수 있다고 판단하여 쿼리때 제공되는 key와 동일한 index를 아래와 같이 설계하기로 결정하였다.
{device:1, name:1, createdAt:-1}
4. 인덱스 튜닝 결과
4.1. Index Access
이전 설계를 그대로 가져갈 경우, 아래와 같이 access를 하지 않는 인덱스를 많이 볼 수 있었다. 따라서 인덱스가 빌드된 만큼의 computing resource를 차지하고 있기 때문에 비효율을 야기시킬 수 있다.
db.items.aggregate([{$indexStats:{}},{$project:{name:1, accesses:1}}])
/* 1 */
{
"name" : "device_-1_name_-1_statisticPeriod_-1_createdAt_-1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 2 */
{
"name" : "device_1_isExported_1_createdAt_-1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
.
.
.
/* 6 */
{
"name" : "createdAt_-1_isExported_-1_statisticPeriod_1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 7 */
{
"name" : "isExported_-1_statisticPeriod_-1_createdAt_-1",
"accesses" : {
"ops" : NumberLong(604388),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
/* 8 */
{
"name" : "isExported_-1_createdAt_-1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
.
.
.
/* 12 */
{
"name" : "factoryName_1",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2022-07-05T10:52:12.533Z")
}
}
불필요한 인덱스를 제거한 결과, 아래와 같이 access가 0인 인덱스가 사라졌다. 그러나, access는 하고 있지만 쿼리가 의도한 인덱스를 타고 있지 않는 경우도 있기 때문에 이 사항도 같이 개선하기로 하였다.
4.2. 카디널리티 분석 ESR Rule 분석을 통한 개선
3.2에서 내린 결론을 토대로 인덱스를 튜닝하고, 의도한 인덱스를 사용하게 한 결과 아래와 같은 결과를 얻을 수 있었다.
db.getCollection('items')
.find(
{
"device":ObjectId("6188cda829424d2f3bf38cf0"),
"name":"Tap Position",
"createdAt":{
$gt:ISODate("2021-11-08 07:13:40.000Z"),
$lt:ISODate("2022-11-08 07:13:40.000Z")
},
"second":{
$in:[0, 10, 20, 30, 40, 50]
}
}
)
._addSpecial('$hint', {
"name" : -1,
"createdAt" : -1,
"seconds" : -1
}
)
.explain("executionStats")
db.getCollection('items')
.find(
{
"device":ObjectId("6188cda829424d2f3bf38cf0"),
"name":"Tap Position",
"createdAt":{
$gt:ISODate("2021-11-08 07:13:40.000Z"),
$lt:ISODate("2022-11-08 07:13:40.000Z")
}
}
)
._addSpecial('$hint', {
"device" : 1,
"name" : 1,
"createdAt" : -1
}
)
.explain("executionStats")
주요 지표만 정리를 하면 다음과 같다.
totalKeyExamined : 13771515 → 49
executionTimeMillis : 37461 → 163
더 적은 수의 key를 examine하고, 같은 값을 구하는데 더 적은 실행시간을 사용하게 되었다. 따라서 인덱스 튜닝을 함으로써 얻을 수 있는 효과를 얻었다고 할 수 있다.
4.3. 총평
위 분석을 통하여 얻어낸 결과 뿐만아니라, 다른 인덱스에 대해서도 전체적인 튜닝을 진행한 결과 전체적으로 많은 computing resource를 줄일 수 있었다.
item collection 개선 전 stat

item collection 개선 후 stat
statisticItem 개선 전 stat

statisticItem collection 개선 후 stat
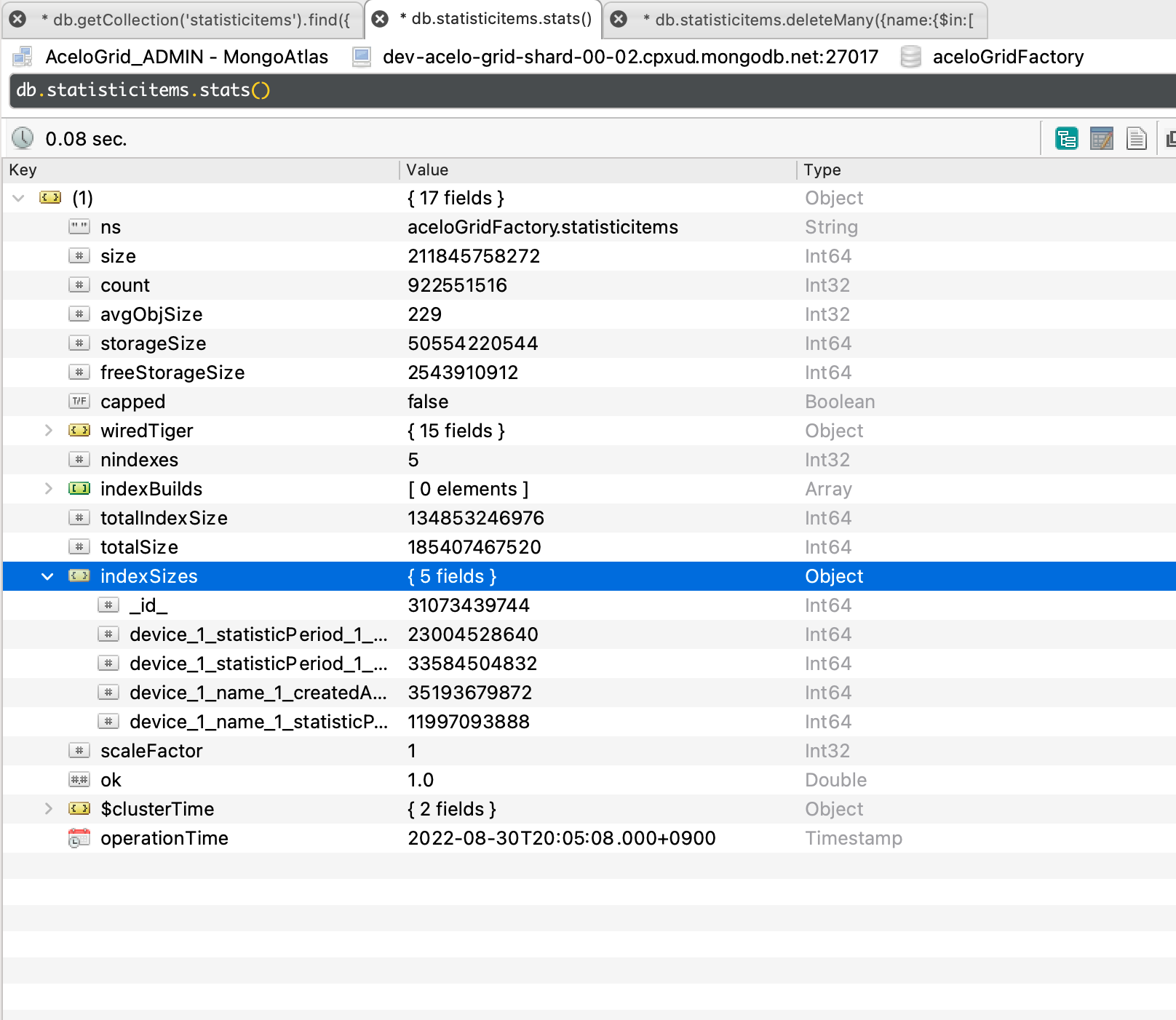
- 2번째 인덱스는 4번째 인덱스로 튜닝되어 사라질 예정이다.
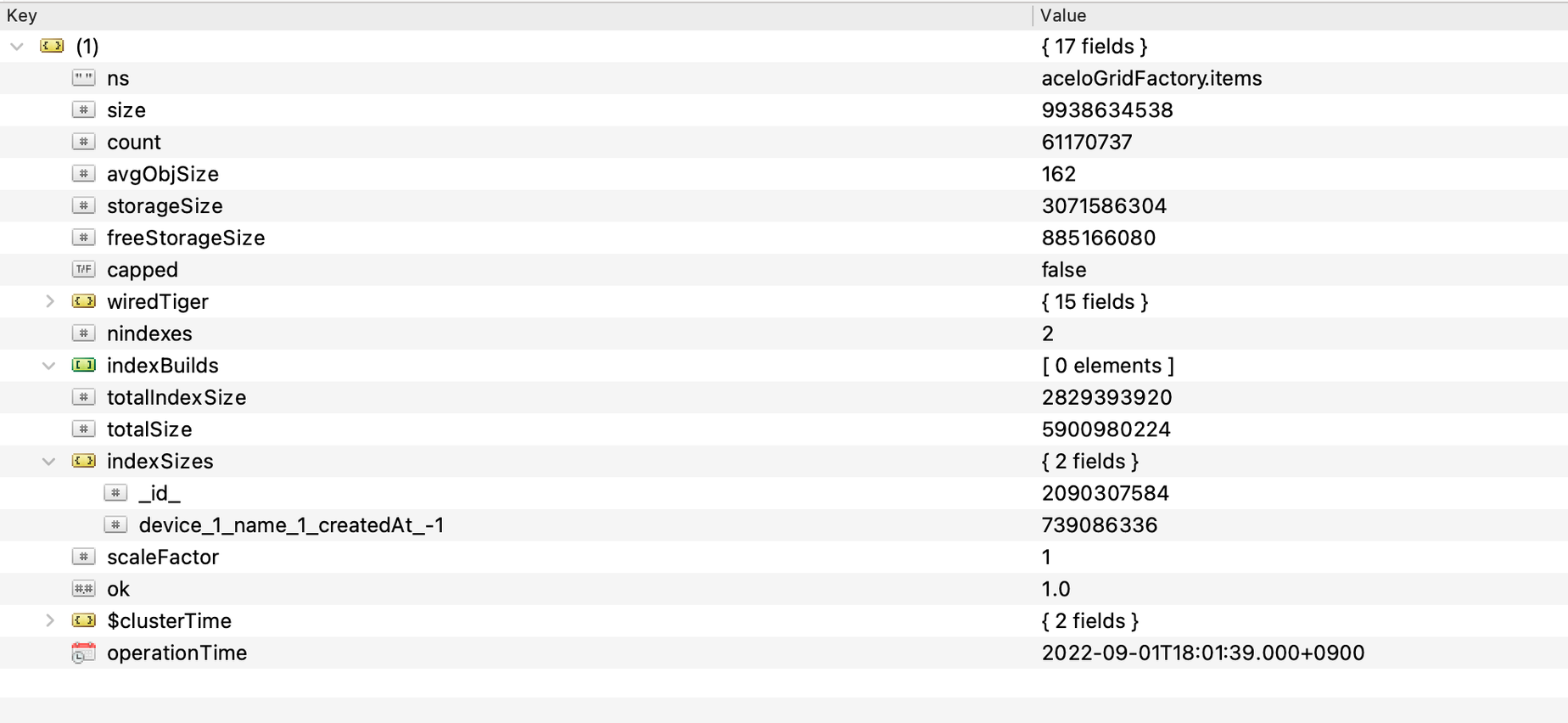
item collection (기존 대비 약 28.4% 수준으로 개선)
- 개선 전 index size : 9932357632 bytes
- 개선 후 index size : 2829393920 bytes
statistic collection (기존대비 약 76.7% 수준으로 개선, 사라질 예정인 index 제거시, 약 57.6% 까지 개선 가능)
- 개선 전 index size : 175649067008 bytes
- 개선 후 index size : 134853246976 bytes (사라질 예정인 index 제거시, 101268742144 bytes)
5. 후기 및 다음 작업에 대한 예고
인덱스는 db query 성능을 dramatic하게 향상시켜주는 요소이다. 그러나 이를 효율적이지 못한 방향을 쓰고, 정리를 지속적으로 하지 않다 보니 이에 대한 비용이 많이 발생하는 상황이 발생하였다. 작업 후에 상당한 자원이 삭제가 된 것을 겪고나서는 운영중인 서비스에 대한 인덱스에 대해서 지속적으로 리뷰를 하고, 새로운 인덱스를 생성시 개발자 간 소통을 통해서 효율적으로 설계하는 쪽으로 규칙을 정했다.
다음 작업의 경우, 샤딩이다. 현재 Mongo Atlas의 경우, stard는 primary 1, secondary 2로 나누어져 있으며 단순 데이터 복제만 이루어져 있는 것을 확인하였다.
시계열 데이터기 때문에 지속적으로 대량의 데이터가 쌓이다보면 인덱스가 있더라도 성능이 저하된다. 따라서 shard key를 데이터 생성시간 기준으로 해서 적절히 수평 샤딩을 수행하여 속도를 개선해야할거같다.